Kafka is distributed , partitioned and replicated commit log/msg service.
Kafka runs on a Cluster.The nodes in the Cluster are called as Brokers.
Data that you send or read from Kafka are called as "Messages".Each Message has a Key,Value and TimeStamp.
Message is the unit of data in Kafka and it resembles to record/row in RDBMS world.This message has a optional bit of metadata called key.
Messages are written to a Topic in a Kafka.
Think of a Topic as a database ,we can create our own Topic and then write messages/data to these topics.
Producers are something that will write data to a Topic.This is Push based.
Consumers are something that will read data from a Topic.This is Pull based.
Topic is split into multiple Partitions.Data when you write into a Topic will go into one of the partition of the topic.
The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
These partitions are spread across multiple machines/Node .A single partitions CANNOT be split into different nodes.
These partitions are also replicated on different nodes.Each message in a partition will get a unique increasing sequence number.
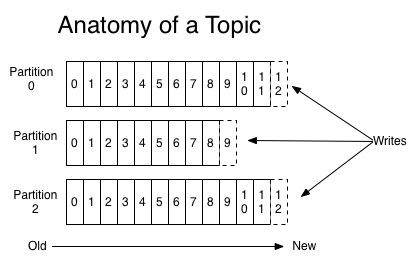
So each message is identified in Kafka by the given topic,the partition and the correspoding sequence Number.
Multiple downstreams via consumers can read this data by giving the topic,the partition and the correspoding sequence Number..
A Topic is split into Partitions. Each partition is replicated.Say we have a Topic T1.Now this wil have partitions p1,p2,p3.
p1 will reside in Node N1 and p2 in Node N2 and p3 in Node N3.
p1 replicas will be in N2 and N3.Here N1 is the Leader for Partition p1
p2 replicas will be in N1 and N3.Here N2 is the Leader for Partition p2.
p3 replicas will be in N1 and N1.Here N3 is the Leader for Partition p3.
Client will interact only with the Leader Node for a given partition.
We have something called as Consumer Group.These consists of Consumers.
One Partition cannot be read by two or more consumers belonging to a Consumer Group.This will avoid duplication in Consumer.
The offset is another bit of metadata—an integer value that continually increases—that Kafka adds to each message as it is produced. Each message in a given partition has a unique offset. By storing the offset of the last consumed message for each partition, either in Zookeeper or in Kafka itself, a consumer can stop and restart without losing its place.
Its the broker which receives the message that assigns offset to the message.
So for a given consumer group,the number of consumers can be less or equal to the number of partitions for a given topic.